Deep learning using Pytorch on Images dataset
The CIFAR-10 dataset is a widely used collection of images in the field of machine learning. It consists of 60,000 32x32 color images categorized into 10 different classes, with each class containing 6,000 images. These classes include airplanes, automobiles, birds, cats, deer, dogs, frogs, horses, rabbits, and ships.
In the PyTorch vision library, the CIFAR-10 dataset can be easily accessed and utilized. PyTorch provides a convenient way to download the dataset and offers various transformations to preprocess the images for training and testing machine learning models. This makes it a popular choice for training and evaluating image classification algorithms.
In this blog we will train a deep neural network on the CIFAR10 image dataset.
I have utilized Jupyter Notebook, which is installed on my Mac, to run my code. However, an excellent alternative is Google Colab, which allows for seamless execution of the code presented in this blog.
In order to work with the code effectively, there are specific packages that I need to install within my virtual environment. These packages include:
PyTorch: A powerful deep learning library that provides flexibility and ease of use for building and training neural networks.
TorchMetrics: A library that offers a wide range of metrics specifically designed for evaluating the performance of generative models.
TorchVision: A package that simplifies the process of loading and preprocessing datasets, including the popular CIFAR-10 dataset, which contains a variety of images used for training machine learning models.
By setting up these packages, I can leverage the capabilities of deep learning and effectively work with image data.
Loading Packages and CIFAR-10 DataSet
Lets load the packages needed
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms.v2 as T
We will detects and selects the best available device for PyTorch computations
if torch.cuda.is_available():
device = "cuda"
elif torch.backends.mps.is_available():
device = "mps"
else:
device = "cpu"
Using TorchVision we will load the dataset and split into train, test and valid dataset.
We create a preprocessing pipeline that transforms images as they're loaded:
T.Compose([...]) - Chains multiple transforms together in sequence. Each transform is applied in order.
T.ToImage() - Converts images from various formats (PIL images, NumPy arrays, raw tensors) into TorchVision's Image class (a specialized tensor type). Standardizes the image format.
T.ToDtype(torch.float32, scale=True) - Converts image values to 32-bit floats and scales them:
torch.float32 - Sets data type to float32
scale=True - Normalizes pixel values from their original range (0-255 for typical images) to 0.0-1.0
toTensor = T.Compose([T.ToImage(), T.ToDtype(torch.float32, scale=True)])
train_and_valid_set = torchvision.datasets.CIFAR10(
root="datasets", train=True, download=True, transform=toTensor
)
test_set= torchvision.datasets.CIFAR10(
root="datasets", train=False, download=True, transform=toTensor
)
Randomly splits (50,000 CIFAR-10 training images) into two subsets:
train_set → 45,000 images (for training)
valid_set → 5,000 images (for validation/testing model performance during training)
torch.manual_seed(42)
train_set, valid_set = torch.utils.data.random_split(
train_and_valid_set, [45_000, 5_000]
)
Now load the datasets as python’s DataLoader objects
batch_size = 128
train_loader = torch.utils.data.DataLoader(
dataset=train_set, batch_size=batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(
dataset=valid_set, batch_size=batch_size, shuffle=False
)
test_loader = torch.utils.data.DataLoader(
dataset=test_set, batch_size=batch_size, shuffle=False
)
Build the Model(Deep Neural Network)
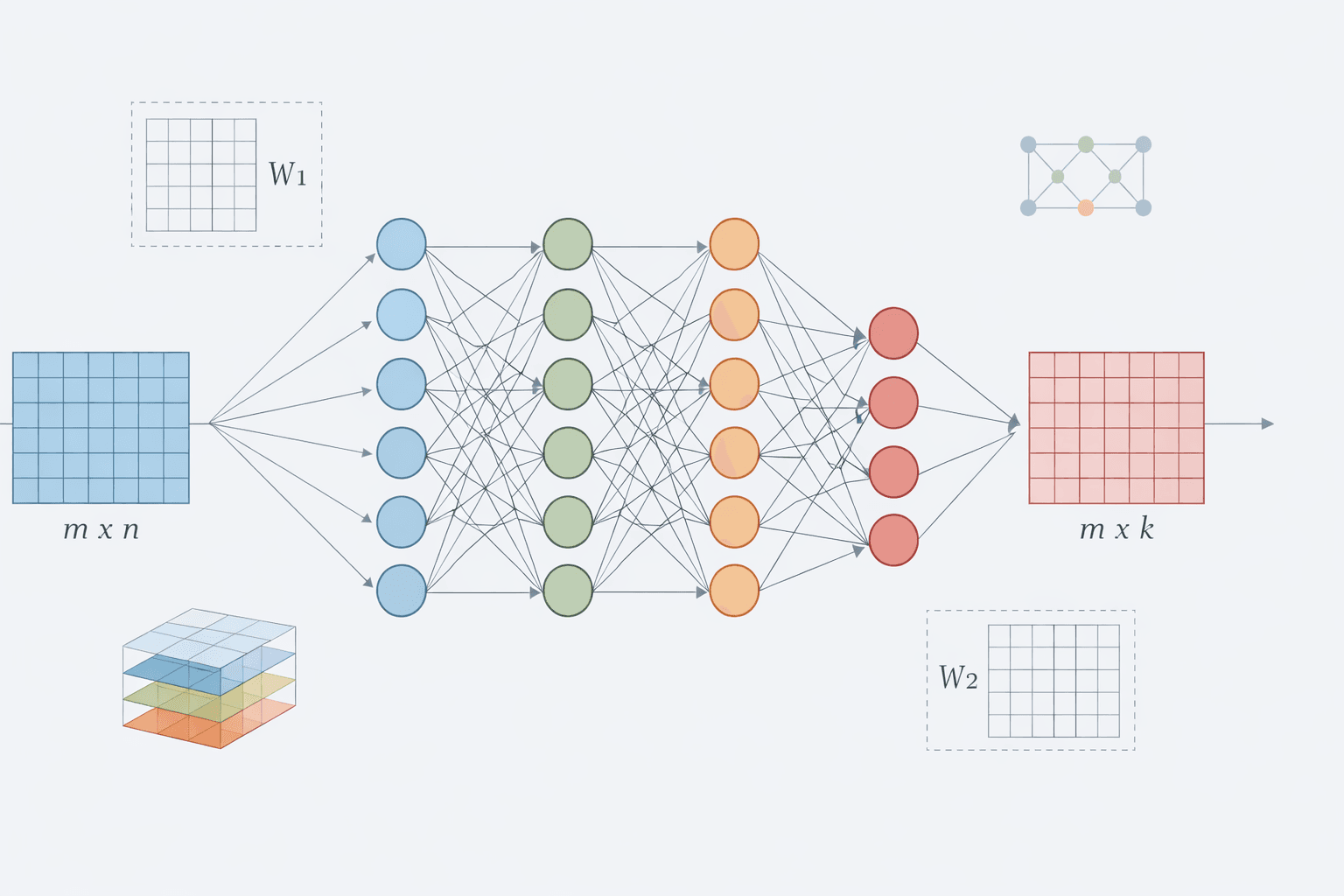
We will build a deep neural network (DNN) with 20 hidden layers, each containing 100 neurons. We will use He initialization for the weights and the Swish activation function (implemented as nn.SiLU). Since this is a classification task, the output layer will have one neuron for each class.
He Initialization
We will use He Initialization (also known as Kaiming Initialization) which is a technique for initializing weights in neural networks that use ReLU (Rectified Linear Unit) or Swish/SiLU activation functions.
The Problem It Solves:
When training deep networks, weights that are initialized randomly can lead to several issues:
Vanishing Gradients: Gradients can become very small, causing learning to slow down significantly.
Exploding Gradients: Gradients can grow too large, resulting in unstable training.
How It Works:
He initialization scales the weights based on the number of input neurons to the layer:
\([ w \sim U(-\sqrt{\frac{6}{n_{\text{in}}}}, \sqrt{\frac{6}{n_{\text{in}}}}) ]\)
where \(( n_{\text{in}} ) \) is the number of input neurons for that layer.
Layers with more input neurons will have smaller weight magnitudes. This approach helps maintain consistent signal variance throughout the network.
Why It Matters:
Faster Convergence: The network trains more efficiently.
Better Performance for Deeper Networks: It helps prevent gradient-related issues in very deep architectures.
Optimized for ReLU/SiLU: Specifically tuned for these activation functions.
Without He initialization, training a 20-layer network (like yours) would be challenging. With it, deep networks can learn significantly faster and more stably.
def use_he_init(module):
if isinstance(module, torch.nn.Linear):
torch.nn.init.kaiming_uniform_(module.weight)
torch.nn.init.zeros_(module.bias)
Now we build Deep Neural Network of 20 hidden layers, each containing 100 neurons and using activation function SiLU
def build_deep_model(n_hidden, n_neurons, n_inputs, n_outputs):
layers = [nn.Flatten(), nn.Linear(n_inputs, n_neurons), nn.SiLU()]
for _ in range(n_hidden - 1):
layers += [nn.Linear(n_neurons, n_neurons), nn.SiLU()]
layers += [nn.Linear(n_neurons, n_outputs)]
model = torch.nn.Sequential(*layers)
model.apply(use_he_init)
return model
Activation Function SiLU
SiLU (Sigmoid Linear Unit), also known as Swish, is a smooth activation function that has gained popularity in modern deep learning.
Mathematical Definition:
\(\mathbf{ \text{SiLU}(x) = x \cdot \sigma(x) = x \cdot \frac{1}{1 + e^{-x}} }\)
Here, \(\mathbf{ \sigma(x) }\) represents the sigmoid function.
How It Works:
The function multiplies the input ( x ) by its sigmoid value, which lies between 0 and 1.
When ( x ) is negative, the sigmoid value approaches 0, resulting in a small output.
When ( x ) is positive, the sigmoid value approaches 1, making the output close to ( x ).
This creates a smooth, non-linear curve.
Key Advantages:
Smoothness: Unlike ReLU, which has a sharp corner at 0, SiLU is smooth everywhere.
Self-gating: The sigmoid component acts as a "gate," determining which activations can pass through.
Better Gradient Flow: It helps prevent issues related to vanishing or exploding gradients in deep networks.
Compatibility with He Initialization: SiLU is designed to work effectively with He weight initialization.
Comparison to ReLU:
ReLU: Returns \(( \max(0, x) ) \) – it is fast but has a sharp transition.
SiLU: Returns \(( x \cdot \sigma(x) ) \) – it is smoother and more expressive.
Below shows three functions Sigmoid , SiLU(Swish) and ReLU activation functions

Now we build the model calling our function build_deep_model
torch.manual_seed(42)
# build the model
model = build_deep_model(n_hidden=20, n_neurons=100, n_inputs=3 * 32 * 32, n_outputs=10)
model.to(device)
Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=3072, out_features=100, bias=True)
(2): SiLU()
(3): Linear(in_features=100, out_features=100, bias=True)
(4): SiLU()
(5): Linear(in_features=100, out_features=100, bias=True)
(6): SiLU()
(7): Linear(in_features=100, out_features=100, bias=True)
(8): SiLU()
(9): Linear(in_features=100, out_features=100, bias=True)
(10): SiLU()
(11): Linear(in_features=100, out_features=100, bias=True)
(12): SiLU()
(13): Linear(in_features=100, out_features=100, bias=True)
(14): SiLU()
(15): Linear(in_features=100, out_features=100, bias=True)
(16): SiLU()
(17): Linear(in_features=100, out_features=100, bias=True)
(18): SiLU()
(19): Linear(in_features=100, out_features=100, bias=True)
(20): SiLU()
(21): Linear(in_features=100, out_features=100, bias=True)
(22): SiLU()
(23): Linear(in_features=100, out_features=100, bias=True)
...
(38): SiLU()
(39): Linear(in_features=100, out_features=100, bias=True)
(40): SiLU()
(41): Linear(in_features=100, out_features=10, bias=True)
)
Train the model
Now we will write a function that trains a neural network with early stopping to prevent overfitting. Here's what it does:
History Tracking: The function sets up a system to track losses and metrics during training.
Metric Calculation: It calculates both training and validation metrics at each epoch.
Validation Improvement:
- If the validation metric improves, the function saves the model weights and resets the patience counter to zero.
No Improvement Case:
If the validation metric does not improve, the function increments the patience counter.
After a specified number of epochs without improvement (the patience threshold), training is stopped early.
Restoring the Best Model: The function restores the model to the version with the highest validation metric.
Why This Matters:
Prevents Overfitting: Early stopping helps to stop training before the model memorizes the training data.
Saves the Best Model: It retains the checkpoint that exhibits the best validation performance.
Efficiency: This approach avoids unnecessary training once the model's performance plateaus.
# This function evaluates a trained model on a dataset and computes a metric #(like accuracy) def evaluate_tm(model, data_loader, metric): model.eval() metric.reset() with torch.no_grad(): for X_batch, y_batch in data_loader: X_batch, y_batch = X_batch.to(device), y_batch.to(device) y_pred = model(X_batch) metric.update(y_pred, y_batch) return metric.compute() def train_with_early_stopping(model, optimizer, loss_fn, metric, train_loader, valid_loader, n_epochs, patience=10, checkpoint_path=None, scheduler=None): checkpoint_path = checkpoint_path or "my_checkpoint.pt" history = {"train_losses": [], "train_metrics": [], "valid_metrics": []} best_metric = 0.0 patience_counter = 0 for epoch in range(n_epochs): total_loss = 0.0 metric.reset() model.train() t0 = time.time() for X_batch, y_batch in train_loader: X_batch, y_batch = X_batch.to(device), y_batch.to(device) y_pred = model(X_batch) loss = loss_fn(y_pred, y_batch) total_loss += loss.item() loss.backward() optimizer.step() optimizer.zero_grad() metric.update(y_pred, y_batch) train_metric = metric.compute().item() valid_metric = evaluate_tm(model, valid_loader, metric).item() if valid_metric > best_metric: torch.save(model.state_dict(), checkpoint_path) best_metric = valid_metric best = " (best)" patience_counter = 0 else: patience_counter += 1 best = "" t1 = time.time() history["train_losses"].append(total_loss / len(train_loader)) history["train_metrics"].append(train_metric) history["valid_metrics"].append(valid_metric) print(f"Epoch {epoch + 1}/{n_epochs}, " f"train loss: {history['train_losses'][-1]:.4f}, " f"train metric: {history['train_metrics'][-1]:.4f}, " f"valid metric: {history['valid_metrics'][-1]:.4f}{best}" f" in {t1 - t0:.1f}s" ) if scheduler is not None: scheduler.step() if patience_counter >= patience: print("Early stopping!") break model.load_state_dict(torch.load(checkpoint_path)) return historyLet's use the NAdam optimizer with a learning rate set to 0.002.
NAdam (Nesterov-accelerated Adaptive Moment Estimation) is an advanced optimizer that combines two powerful techniques:
A variant of the Adam optimizer that adds Nesterov momentum
Designed to improve convergence speed and training stability
Key Advantages Over Adam:
Faster convergence - Nesterov momentum helps avoid oscillations
Better final performance - Often achieves lower final loss
Adaptive learning rates - Still maintains per-parameter learning rates like Adam
Good for deep networks - Especially effective with deep architectures
optimizer = torch.optim.NAdam(model.parameters(), lr=2e-3) criterion = nn.CrossEntropyLoss() accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=10).to(device)Now we will call the training function
n_epochs = 100 # now we will call the training function history = train_with_early_stopping( model, optimizer, criterion, accuracy, train_loader, valid_loader, n_epochs )
Epoch 1/100, train loss: 2.0548, train metric: 0.2134, valid metric: 0.1974 (best) in 4.1s
Epoch 2/100, train loss: 1.9637, train metric: 0.2550, valid metric: 0.2746 (best) in 4.0s
Epoch 3/100, train loss: 1.8881, train metric: 0.2879, valid metric: 0.3152 (best) in 3.9s
Epoch 4/100, train loss: 1.8266, train metric: 0.3196, valid metric: 0.2904 in 3.9s
...
Epoch 29/100, train loss: 1.3953, train metric: 0.5011, valid metric: 0.4284 in 4.0s
Epoch 30/100, train loss: 1.3910, train metric: 0.5036, valid metric: 0.4216 in 4.1s
Epoch 31/100, train loss: 1.3841, train metric: 0.5062, valid metric: 0.4260 in 4.1s
Early stopping!
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
This output shows the training stopped early due to no improvement. Here's what it means:
Key Observations:
Train > Valid accuracy gap (50.62% vs 42.60%) - Shows some overfitting, but this is expected
Stopped at epoch 31 - Saved time and computational resources by not training all 100 epochs
Model restored - The best model checkpoint (from epoch 21) was automatically loaded
Test the Model
We will test the model on test set
test_accuracy = evaluate_tm(model, test_loader, accuracy).item()
print(f"\nTest Accuracy: {test_accuracy:.4f} ({test_accuracy*100:.2f}%)")
Test Accuracy: 0.4377 (43.77%)
Charts
Lets draw the charts for training loss over epochs and Accuracy over epochs
# Plot training history
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# Plot loss
epochs_range = range(1, len(history['train_losses']) + 1)
axes[0].plot(epochs_range, history['train_losses'], 'b-', linewidth=2, label='Train Loss')
axes[0].set_xlabel('Epoch', fontsize=12)
axes[0].set_ylabel('Loss', fontsize=12)
axes[0].set_title('Training Loss Over Epochs', fontsize=14, fontweight='bold')
axes[0].grid(True, alpha=0.3)
axes[0].legend()
# Plot accuracy
axes[1].plot(epochs_range, history['train_metrics'], 'g-', linewidth=2, label='Train Accuracy')
axes[1].plot(epochs_range, history['valid_metrics'], 'r-', linewidth=2, label='Valid Accuracy')
axes[1].set_xlabel('Epoch', fontsize=12)
axes[1].set_ylabel('Accuracy', fontsize=12)
axes[1].set_title('Accuracy Over Epochs', fontsize=14, fontweight='bold')
axes[1].grid(True, alpha=0.3)
axes[1].legend()
plt.tight_layout()
plt.show()
# Print summary
print("\n" + "="*50)
print("TRAINING SUMMARY")
print("="*50)
print(f"Total Epochs Trained: {len(history['train_losses'])}")
print(f"Final Train Loss: {history['train_losses'][-1]:.4f}")
print(f"Final Train Accuracy: {history['train_metrics'][-1]:.4f} ({history['train_metrics'][-1]*100:.2f}%)")
print(f"Final Valid Accuracy: {history['valid_metrics'][-1]:.4f} ({history['valid_metrics'][-1]*100:.2f}%)")
print(f"Best Valid Accuracy: {max(history['valid_metrics']):.4f} ({max(history['valid_metrics'])*100:.2f}%)")
print("="*50)